
Synthetic Data Generation For Ai Training Market Size and Growth Forecast 2026-2030
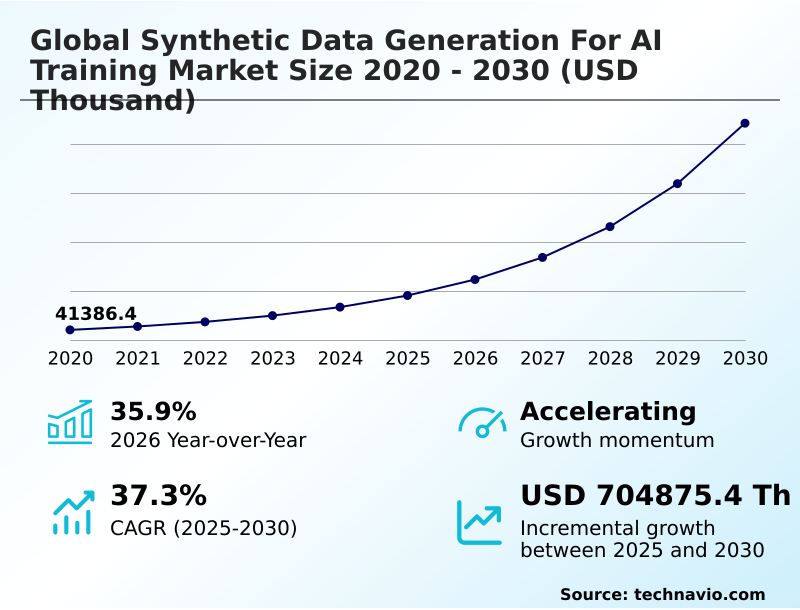
The Synthetic Data Generation For Ai Training Market size was valued at USD 182.01 million in 2025 growing at a CAGR of 37.3% during the forecast period 2026-2030.
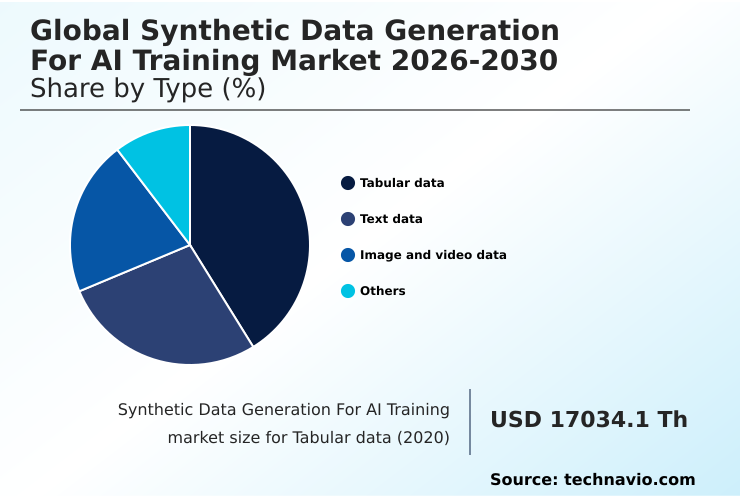
North America accounts for 37.6% of incremental growth during the forecast period. The Tabular data segment by Type was valued at USD 55.56 million in 2024, while the BFSI segment holds the largest revenue share by End-user.
The market is projected to grow by from 2020 to 2030, with USD 704.88 million of the growth expected during the forecast period of 2025 to 2030.
Get Key Insights on Market Forecast (PDF) Request Free Sample
Synthetic Data Generation For Ai Training Market Overview
The synthetic data generation for ai training market is expanding as organizations navigate stringent data privacy laws like GDPR and CCPA, which restrict the use of real-world personal information. This regulatory pressure makes privacy-enhancing technologies and high-fidelity data generation essential for innovation. The core challenge remains preventing model collapse prevention, where AI systems trained on artificial data lose touch with real-world nuances. To address this, developers use generative adversarial networks for statistical property replication, ensuring AI model robustness. For example, a leading automotive manufacturer, by leveraging computer vision simulation and over five billion miles of synthetic sensor data for autonomous systems training data, reduced its safety validation timeline by nearly 40%. With North America contributing over 37% of the incremental growth and the overall market accelerating at a 35.9% year-over-year rate, the focus is on creating scalable, trustworthy data scarcity solutions. This includes developing advanced data anonymization techniques and automated data annotation to fuel the next generation of AI.
Drivers, Trends, and Challenges in the Synthetic Data Generation For Ai Training Market
The complexity of modern AI systems necessitates advanced approaches to data provisioning, moving beyond simple data collection.
The use of synthetic data for rare event modeling is now standard practice in safety-critical sectors; for instance, in autonomous driving, billions of simulated miles are used to train models for scenarios that are too dangerous to test physically, demonstrating the value of high-fidelity synthetic data for autonomous driving.
Concurrently, the imperative for generating balanced datasets for AI fairness, mandated by frameworks like the EU AI Act, is reshaping development priorities. This is particularly relevant when training large language models synthetically, as it allows developers to mitigate inherent biases found in web-scraped data and avoid the data exhaustion problem.
A key technical focus is on mitigating model collapse in AI, a phenomenon where models lose diversity when trained on their own output. To counter this, techniques such as privacy-preserving federated learning with synthetic data are being deployed, allowing models to be updated without centralizing sensitive information.
In practice, the time required for synthetic data for computer vision applications can be over 30% faster than traditional methods. Firms creating synthetic data for financial modeling and synthetic medical diagnosis data are leveraging these efficiencies to accelerate innovation while ensuring compliance.
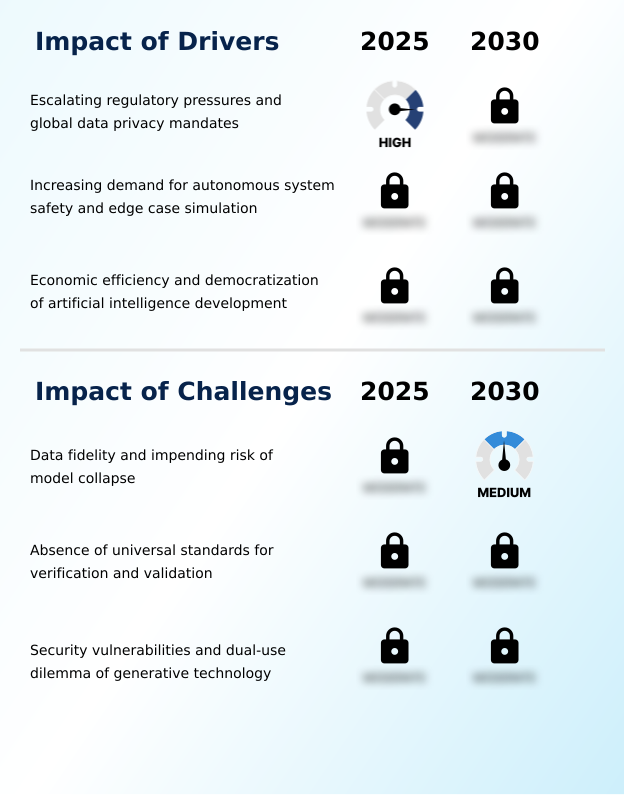
Primary Growth Driver: Escalating regulatory pressures and global data privacy mandates are a key driver for market growth.
Stringent data privacy regulations, including GDPR and CCPA, are a primary driver, compelling organizations to adopt privacy-by-design principles and utilize synthetic data to avoid non-compliance penalties.
Another major factor is the demand for AI model robustness in autonomous systems, which require vast amounts of training data for edge case simulation that is impractical to collect in the real world.
The automotive sector's growing adoption reflects this need. Additionally, economic efficiency accelerates adoption, as automated data anonymization techniques and pre-labeled dataset creation offer a cost-effective alternative to manual data acquisition.
This democratization of AI development also supports algorithmic bias mitigation by enabling the creation of balanced and representative training sets.
Emerging Market Trend: A key trend is the emergence of high-fidelity, multi-modal synthetic environments designed for spatial computing. These advanced simulations are becoming essential for training sophisticated AI applications.
The market is advancing beyond static datasets toward high-fidelity, multi-modal synthetic environments. This trend is driven by demand from spatial computing and robotics, which require synchronized data for applications like AI gesture recognition.
A significant development is the convergence of synthetic data generation with federated learning integration, a technique gaining momentum in APAC, which is projected to grow at a CAGR of 38.0%. This approach addresses data sovereignty and privacy concerns.
Furthermore, the industry is moving toward autonomous data curation through closed-loop training systems, where AI models identify their own performance gaps and request specific synthetic datasets to improve, indicating a maturation of AI-powered fraud detection and optimization capabilities.
Key Industry Challenge: Maintaining data fidelity and mitigating the impending risk of model collapse represent a key challenge affecting industry growth.
A significant technical challenge is maintaining data fidelity to prevent model collapse, where AI models degrade after being trained on their own synthetic outputs. This requires sophisticated methods for ensuring statistical property replication without sacrificing diversity.
The absence of universal standards for AI model validation creates adoption friction, especially in safety-critical industries that require verifiable quality benchmarks, a need highlighted by the formation of a global standards committee in July 2025.
Moreover, the dual-use nature of generative adversarial networks presents a security risk, as the technology can be used for malicious purposes like creating deepfakes, demanding robust AI training data security and provenance technologies to ensure responsible use.
Explore Full Market Dynamics Analysis Request Free Sample
Synthetic Data Generation For Ai Training Market Segmentation
The synthetic data generation for ai training industry research report provides comprehensive data including region-wise segment analysis, with forecasts and analysis for the period 2026-2030, as well as historical data from 2020-2024 for the following segments.
Type Segment Analysis
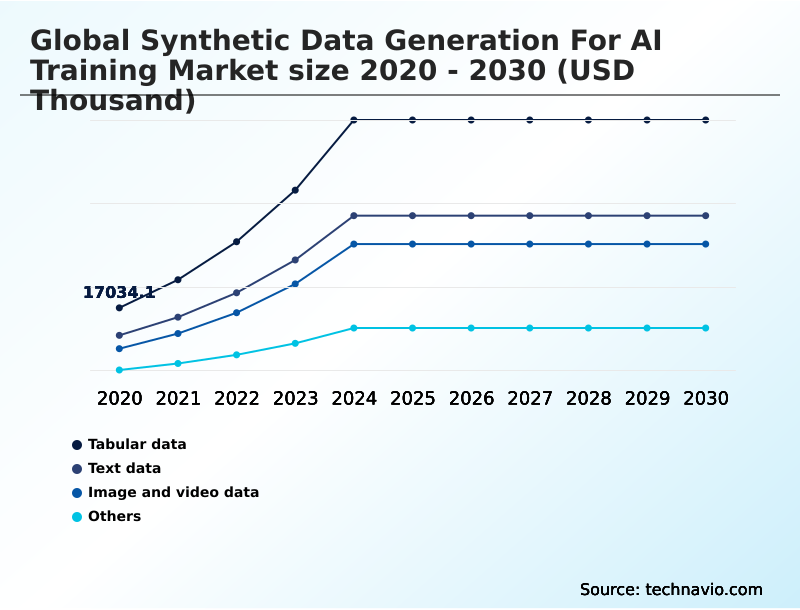
The tabular data segment is estimated to witness significant growth during the forecast period.
The synthetic data generation for ai training market is segmented by data type and end-user, addressing distinct operational needs.
Tabular data, which includes synthetic tabular data generation, is pivotal for regulated sectors like BFSI and healthcare, where privacy-enhancing technologies are mandated for applications such as AI-powered risk assessment.
Image and video data are essential for computer vision simulation and providing autonomous systems training data.
The BFSI segment represents a significant portion of end-user demand, driven by strict regulatory data compliance needs under frameworks like the General Data Protection Regulation (GDPR).
This necessity for secure, high-quality information to train models without compromising sensitive data underpins the market's structure and growth, with North America leading in adoption, contributing over 37% of the market opportunity.
The Tabular data segment was valued at USD 55.56 million in 2024 and showed a gradual increase during the forecast period.
Synthetic Data Generation For Ai Training Market by Region: North America Leads with 37.6% Growth Share
North America is estimated to contribute 37.6% to the growth of the global market during the forecast period.
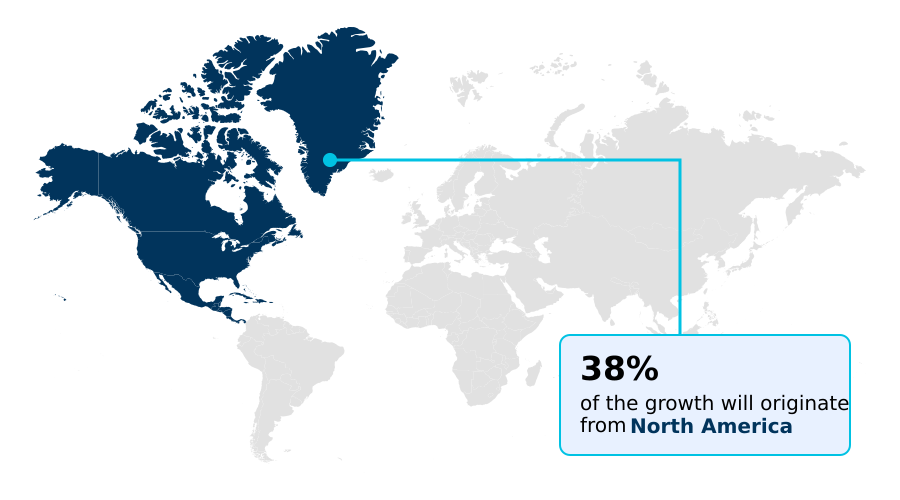
The geographic landscape is led by North America, which accounts for over 37% of the global market opportunity, driven by advanced autonomous vehicle simulation and AI model validation requirements in its established technology sector.
Europe, representing nearly 28% of the market, prioritizes regulatory data compliance under GDPR, fueling adoption in finance and healthcare.
The fastest growth is in APAC, which holds a 25% market share and is propelled by large-scale AI in smart cities projects and manufacturing modernization. These initiatives demand sophisticated sensor data simulation and AI-driven data curation.
Across all regions, the need for data sovereignty solutions is accelerating the deployment of localized platforms for synthetic data for cybersecurity and other critical applications, ensuring that generative AI for NLP and other models can be trained without cross-border data transfers.
Customer Landscape Analysis for the Synthetic Data Generation For Ai Training Market
The synthetic data generation for ai training market forecasting report includes the adoption lifecycle of the market, covering from the innovator’s stage to the laggard’s stage. It focuses on adoption rates in different regions based on penetration. Furthermore, the synthetic data generation for ai training market report also includes key purchase criteria and drivers of price sensitivity to help companies evaluate and develop their market growth analysis strategies.
Competitive Landscape of the Synthetic Data Generation For Ai Training Market
Companies are implementing various strategies, such as strategic alliances, partnerships, mergers and acquisitions, geographical expansion, and product/service launches, to enhance their presence in the synthetic data generation for ai training market industry.
Anonos. - Offerings focus on generating privacy-preserving data assets through advanced anonymization, enabling secure AI model development while maintaining strict regulatory compliance.
The industry research and growth report includes detailed analyses of the competitive landscape of the market and information about key companies, including:
- Anonos.
- BetterData Pte Ltd.
- Broadcom Inc.
- Capgemini SE
- DataGen
- Facteus Inc
- GenRocket Inc.
- Gretel AI
- IBM Corp.
- Informatica Inc.
- K2view Ltd.
- MDClone Ltd.
- MOSTLY AI
- NVIDIA Corp.
- Parallel Domain
- Rendered.ai
- Synthesise AI.
- Syntho
- Tonic AI Inc.
- YData Labs Inc
Qualitative and quantitative analysis of companies has been conducted to help clients understand the wider business environment as well as the strengths and weaknesses of key industry players. Data is qualitatively analyzed to categorize companies as pure play, category-focused, industry-focused, and diversified; it is quantitatively analyzed to categorize companies as dominant, leading, strong, tentative, and weak.
Recent Developments in the Synthetic Data Generation For Ai Training Market
- In January, 2025, a leading technology corporation in Seattle launched an initiative to provide synthetic datasets for simulating complex weather patterns to assist disaster response teams.
- In February, 2025, a major national space exploration agency in the United States initiated a public-private partnership to develop high-resolution synthetic imagery of lunar and Martian surfaces for training autonomous rovers.
- In March, 2025, a leading telecommunications equipment provider in North America utilized synthetic network traffic data to test the scalability of its new cloud-native core architecture before its official product launch.
- In April, 2025, a prominent engineering firm in Stuttgart revealed a new synthetic simulation platform designed for training collaborative robots that work alongside human operators in industrial settings.
Research Analyst Overview: Synthetic Data Generation For Ai Training Market
The increasing reliance on generative adversarial networks and variational autoencoders is fundamentally shifting enterprise focus from data acquisition to the quality assurance of synthesized information. This transition compels a strategic re-evaluation of R&D budgets at the boardroom level, redirecting investment from manual data labeling toward platforms that support high-fidelity data generation and specialized talent for AI model validation.
The BFSI sector's position as the largest end-user, accounting for a significant share of the market, underscores the critical role of privacy-enhancing technologies in regulated industries. Adherence to mandates like the California Consumer Privacy Act (CCPA) is non-negotiable, making statistical property replication a primary vendor qualification criterion.
As multi-modal data synthesis becomes more common for applications like NLP training datasets, ensuring algorithmic bias mitigation is a paramount concern. The ability to provide robust data scarcity solutions while preventing model collapse prevention will differentiate leading providers in this evolving landscape.
Dive into Technavio’s robust research methodology, blending expert interviews, extensive data synthesis, and validated models for unparalleled Synthetic Data Generation For Ai Training Market insights. See full methodology.
| Market Scope | |
|---|---|
| Page number | 313 |
| Base year | 2025 |
| Historic period | 2020-2024 |
| Forecast period | 2026-2030 |
| Growth momentum & CAGR | Accelerate at a CAGR of 37.3% |
| Market growth 2026-2030 | USD 704875.4 thousand |
| Market structure | Fragmented |
| YoY growth 2025-2026(%) | 35.9% |
| Key countries | US, Canada, Mexico, Germany, UK, France, Italy, Spain, The Netherlands, China, India, Japan, South Korea, Australia, Singapore, Saudi Arabia, UAE, South Africa, Israel, Turkey, Brazil, Argentina and Colombia |
| Competitive landscape | Leading Companies, Market Positioning of Companies, Competitive Strategies, and Industry Risks |
Synthetic Data Generation For Ai Training Market: Key Questions Answered in This Report
-
What is the expected growth of the Synthetic Data Generation For Ai Training Market between 2026 and 2030?
-
The Synthetic Data Generation For Ai Training Market is expected to grow by USD 704.88 million during 2026-2030, registering a CAGR of 37.3%. Year-over-year growth in 2026 is estimated at 35.9%%. This acceleration is shaped by escalating regulatory pressures and global data privacy mandates, which is intensifying demand across multiple end-use verticals covered in the report.
-
-
What segmentation does the market report cover?
-
The report is segmented by Type (Tabular data, Text data, Image and video data, and Others), End-user (BFSI, Healthcare, Automotive, IT and telecom, and Others), Product (Fully synthetic data, and Partially synthetic data) and Geography (North America, Europe, APAC, Middle East and Africa, South America). Among these, the Tabular data segment is estimated to witness significant growth during the forecast period, driven by rising adoption across key application areas. Each segment includes detailed qualitative and quantitative analysis, along with historical data from 2020-2024 and forecasts through 2030 with year-over-year growth rates.
-
-
Which regions are analyzed in the report?
-
The report covers North America, Europe, APAC, Middle East and Africa and South America. North America is estimated to contribute 37.6% to market growth during the forecast period. Country-level analysis includes US, Canada, Mexico, Germany, UK, France, Italy, Spain, The Netherlands, China, India, Japan, South Korea, Australia, Singapore, Saudi Arabia, UAE, South Africa, Israel, Turkey, Brazil, Argentina and Colombia, with dedicated market size tables and year-over-year growth for each.
-
-
What are the key growth drivers and market challenges?
-
The primary driver is escalating regulatory pressures and global data privacy mandates, which is accelerating investment and industry demand. The main challenge is data fidelity and impending risk of model collapse, creating operational barriers for key market participants. The report quantifies the impact of each driver and challenge across 2026 and 2030 with comparative analysis.
-
-
Who are the major players in the Synthetic Data Generation For Ai Training Market?
-
Key vendors include Anonos., BetterData Pte Ltd., Broadcom Inc., Capgemini SE, DataGen, Facteus Inc, GenRocket Inc., Gretel AI, IBM Corp., Informatica Inc., K2view Ltd., MDClone Ltd., MOSTLY AI, NVIDIA Corp., Parallel Domain, Rendered.ai, Synthesise AI., Syntho, Tonic AI Inc. and YData Labs Inc. The report provides qualitative and quantitative analysis categorizing companies as dominant, leading, strong, tentative, and weak based on their market positioning. Company profiles include business segment analysis, SWOT assessment, key offerings, and recent strategic developments.
-
Synthetic Data Generation For Ai Training Market Research Insights
Market dynamics are defined by the tension between rapid innovation and the need for regulatory adherence under frameworks like GDPR. This drives demand for data-centric AI platforms that embed privacy by design principles.
For instance, the growing reliance on synthetic healthcare data for AI in clinical trials and AI in drug discovery highlights the need for datasets that are both medically accurate and fully anonymized. While the tabular data segment is larger than the image and video data segment, both are critical for different use cases, from financial modeling to autonomous systems.
The adoption of synthetic data allows organizations to accelerate machine learning development and improve AI ethics and fairness by creating balanced datasets, fundamentally altering how AI models are trained and deployed across industries.
We can help! Our analysts can customize this synthetic data generation for ai training market research report to meet your requirements.
 RIA -
RIA - 
