
Synthetic Data Generation Software Market Size 2026-2030
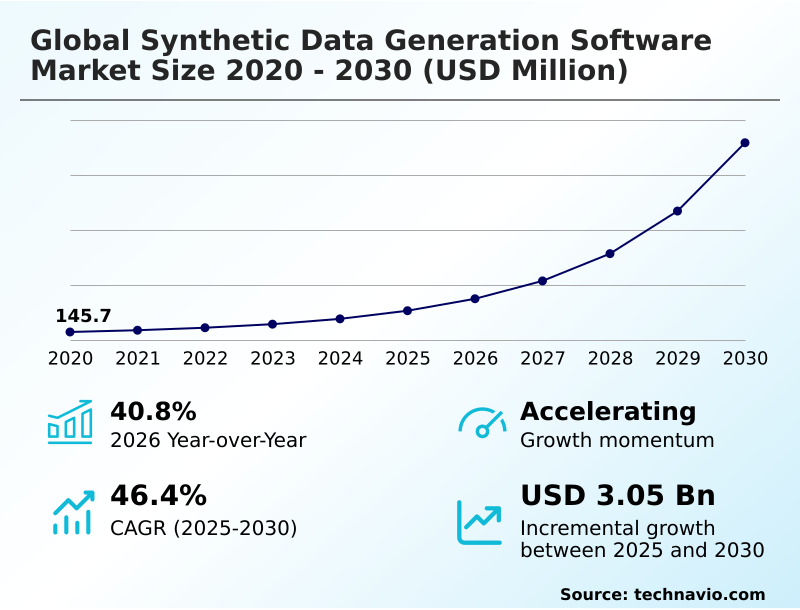
The synthetic data generation software market size is valued to increase by USD 3.05 billion, at a CAGR of 46.4% from 2025 to 2030. Escalating regulatory pressures to protect personal information will drive the synthetic data generation software market.
Major Market Trends & Insights
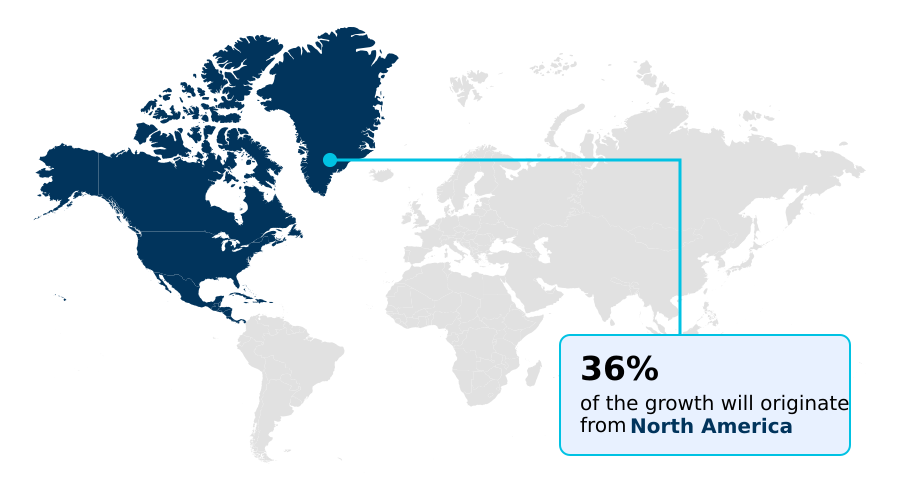
- North America dominated the market and accounted for a 36.4% growth during the forecast period.
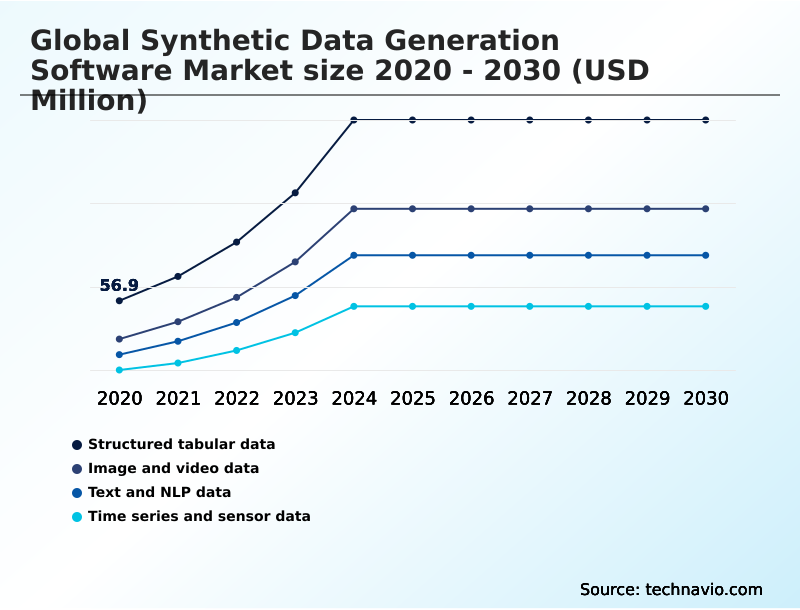
- By Data Type - Structured tabular data segment was valued at USD 147.5 million in 2024
- By End-user - BFSI segment accounted for the largest market revenue share in 2024
Market Size & Forecast
- Market Opportunities: USD 3.44 billion
- Market Future Opportunities: USD 3.05 billion
- CAGR from 2025 to 2030 : 46.4%
Market Summary
- The synthetic data generation software market is expanding as organizations seek to balance innovation with stringent privacy mandates. The indispensable need for diverse and high-volume training data is a primary driver, particularly for complex AI and machine learning models where real-world data is scarce or biased.
- Key trends include the integration of generative AI for high-fidelity data augmentation and the expansion of digital twins for simulating autonomous systems. For example, an automotive firm can generate millions of miles of driving data, including rare edge cases, to train self-driving algorithms without costly physical tests.
- However, the market faces challenges in maintaining data fidelity and preventing model collapse, where AI models trained on synthetic data lose touch with reality. Additionally, integration with legacy systems and the lack of universal standards for synthetic outputs can hinder adoption. Success in this market depends on producing statistically identical, privacy-compliant datasets that accelerate development cycles and reduce costs.
What will be the Size of the Synthetic Data Generation Software Market during the forecast period?
Get Key Insights on Market Forecast (PDF) Get Free Sample
How is the Synthetic Data Generation Software Market Segmented?
The synthetic data generation software industry research report provides comprehensive data (region-wise segment analysis), with forecasts and estimates in "USD million" for the period 2026-2030, as well as historical data from 2020-2024 for the following segments.
- Data type
- Structured tabular data
- Image and video data
- Text and NLP data
- Time series and sensor data
- End-user
- BFSI
- Healthcare and life sciences
- Retail and e-commerce
- Automotive and mobility
- Others
- Application
- AI and ML model training
- Data privacy and compliance testing
- Software testing and QA
- Fraud detection and cybersecurity
- Geography
- North America
- US
- Canada
- Mexico
- Europe
- Germany
- UK
- France
- APAC
- China
- India
- Japan
- Middle East and Africa
- Saudi Arabia
- UAE
- South Africa
- South America
- Brazil
- Argentina
- Colombia
- Rest of World (ROW)
- North America
By Data Type Insights
The structured tabular data segment is estimated to witness significant growth during the forecast period.
The synthetic data generation software market is segmented by data type, with structured tabular data representing a foundational component. This segment involves creating artificial datasets for software testing and QA, which mirror the statistical properties of relational databases.
Organizations rely on these realistic synthetic datasets to bypass legal hurdles associated with sensitive information, improving test coverage by over 40% in some cases. The use of tabular data generation tools is critical for fraud detection and cybersecurity.
Other key segments include the generation of synthetic text and NLP data for training language models, as well as synthetic time series data for forecasting. This approach to data privacy and compliance testing is becoming a standard in data-centric operations.
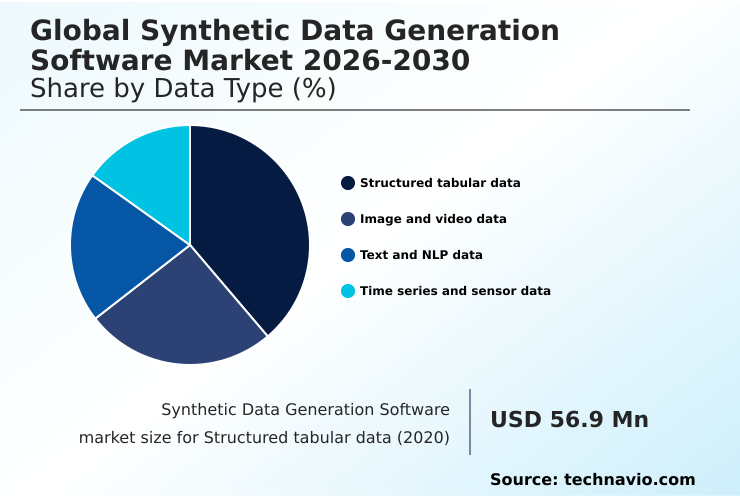
The Structured tabular data segment was valued at USD 147.5 million in 2024 and showed a gradual increase during the forecast period.
Regional Analysis
North America is estimated to contribute 36.4% to the growth of the global market during the forecast period.Technavio’s analysts have elaborately explained the regional trends and drivers that shape the market during the forecast period.
See How Synthetic Data Generation Software Market Demand is Rising in North America Get Free Sample
The geographic landscape is led by North America, which accounts for over 36% of the market’s incremental growth, driven by a mature technology ecosystem.
Here, the focus is on autonomous systems training data and synthetic healthcare data to comply with strict privacy laws. Firms leverage autonomous vehicle simulation data to accelerate development, with some reporting a 40% reduction in physical testing costs.
Meanwhile, APAC is the fastest-growing region, fueled by rapid digital transformation. The use of AI-powered data generation and real-time synthetic data generation is expanding, particularly for synthetic population modeling in smart city projects.
The application of physics-based sensor data and synthetic sensor data simulation is also gaining traction globally to mitigate AI bias with synthetic data and improve the performance of synthetic image and video data models.
Market Dynamics
Our researchers analyzed the data with 2025 as the base year, along with the key drivers, trends, and challenges. A holistic analysis of drivers will help companies refine their marketing strategies to gain a competitive advantage.
- Strategic implementation of synthetic data is becoming a cornerstone for enterprise AI, addressing challenges across multiple domains. The benefits of synthetic data in machine learning are most evident in applications requiring vast, unbiased datasets. For instance, synthetic data for AI model training allows developers to overcome the limitations of scarce real-world information.
- Companies are increasingly focused on the best practices for synthetic data quality to ensure their models are robust. In regulated industries, synthetic data for data privacy compliance is crucial, with specific synthetic data generation software for healthcare and synthetic data generation tools for finance enabling innovation under strict legal frameworks like GDPR.
- The cost of synthetic data generation vs real data presents a compelling economic advantage, often reducing procurement expenses by more than 60%. Use cases are expanding rapidly, from synthetic data for software development testing to complex synthetic data generation in digital twins.
- Specialized techniques are emerging to address how to generate synthetic tabular data and for synthetic data for NLP model development. As firms work to resolve challenges in synthetic data fidelity, the use of synthetic data to reduce AI bias and power synthetic data for fraud detection models is becoming standard practice.
- Comparing synthetic data generation methods helps organizations select the right approach, whether for synthetic data for retail customer analytics, synthetic image data generation for AI, synthetic data for time series forecasting, or synthetic data generation for autonomous vehicles.

What are the key market drivers leading to the rise in the adoption of Synthetic Data Generation Software Industry?
- Escalating regulatory pressures to protect personal information serve as a key driver for the synthetic data generation software market.
- The primary driver for the market is the escalating need for high-quality AI training data generation, which traditional data collection methods cannot satisfy.
- Technologies such as generative adversarial networks are enabling automated data augmentation and balancing imbalanced datasets, which is critical for synthetic data for ML models.
- By facilitating edge case data generation and statistical property mirroring, organizations can train more robust systems, improving failure detection rates by as much as 30%.
- The ability to use data de-identification techniques for creating synthetic financial data or for real-world evidence simulation in healthcare accelerates innovation while ensuring compliance. This AI-powered data generation provides a scalable and cost-effective alternative, enabling privacy-safe innovation.
What are the market trends shaping the Synthetic Data Generation Software Industry?
- The increasing emphasis on robust privacy compliance is driving the proliferation of privacy-enhancing technologies, establishing a primary market trend.
- Key market trends are centered on the adoption of advanced generative AI for data creation and the use of privacy-enhancing technologies. The development of generative diffusion models enables the production of high-fidelity, multi-modal synthetic data, including sophisticated synthetic data for computer vision, which can improve model accuracy by over 25%.
- This trend toward privacy-preserving data synthesis is critical for industries handling sensitive information. Furthermore, digital twin simulation and algorithmic bias mitigation are gaining prominence, with AI model fine-tuning data being generated to ensure fairness and robustness.
- As enterprises scale their AI initiatives, the demand for a seamless synthetic data API to ensure cross-database consistency and facilitate automated data augmentation is growing, with integration speeds improving by up to 60% in modern environments.
What challenges does the Synthetic Data Generation Software Industry face during its growth?
- A key challenge affecting industry growth is the difficulty of maintaining data fidelity while preventing the risk of model collapse in generative models.
- A significant market challenge is ensuring data fidelity validation and preventing model collapse, where AI systems degrade after training on artificial data. The lack of standardized synthetic data quality metrics makes it difficult for organizations to trust the outputs of variational autoencoders and other generative models.
- Integrating a synthetic data platform with legacy systems is another hurdle, often increasing implementation costs by 20-30%. For enterprises adopting agile workflows, creating synthetic test data for DevOps must be seamless, yet complexities in structured tabular data synthesis persist.
- Achieving GDPR compliant data generation requires sophisticated secure data sharing environments to produce high-fidelity synthetic data that is both useful and fully anonymized, a balance that remains technically demanding.
Exclusive Technavio Analysis on Customer Landscape
The synthetic data generation software market forecasting report includes the adoption lifecycle of the market, covering from the innovator’s stage to the laggard’s stage. It focuses on adoption rates in different regions based on penetration. Furthermore, the synthetic data generation software market report also includes key purchase criteria and drivers of price sensitivity to help companies evaluate and develop their market growth analysis strategies.
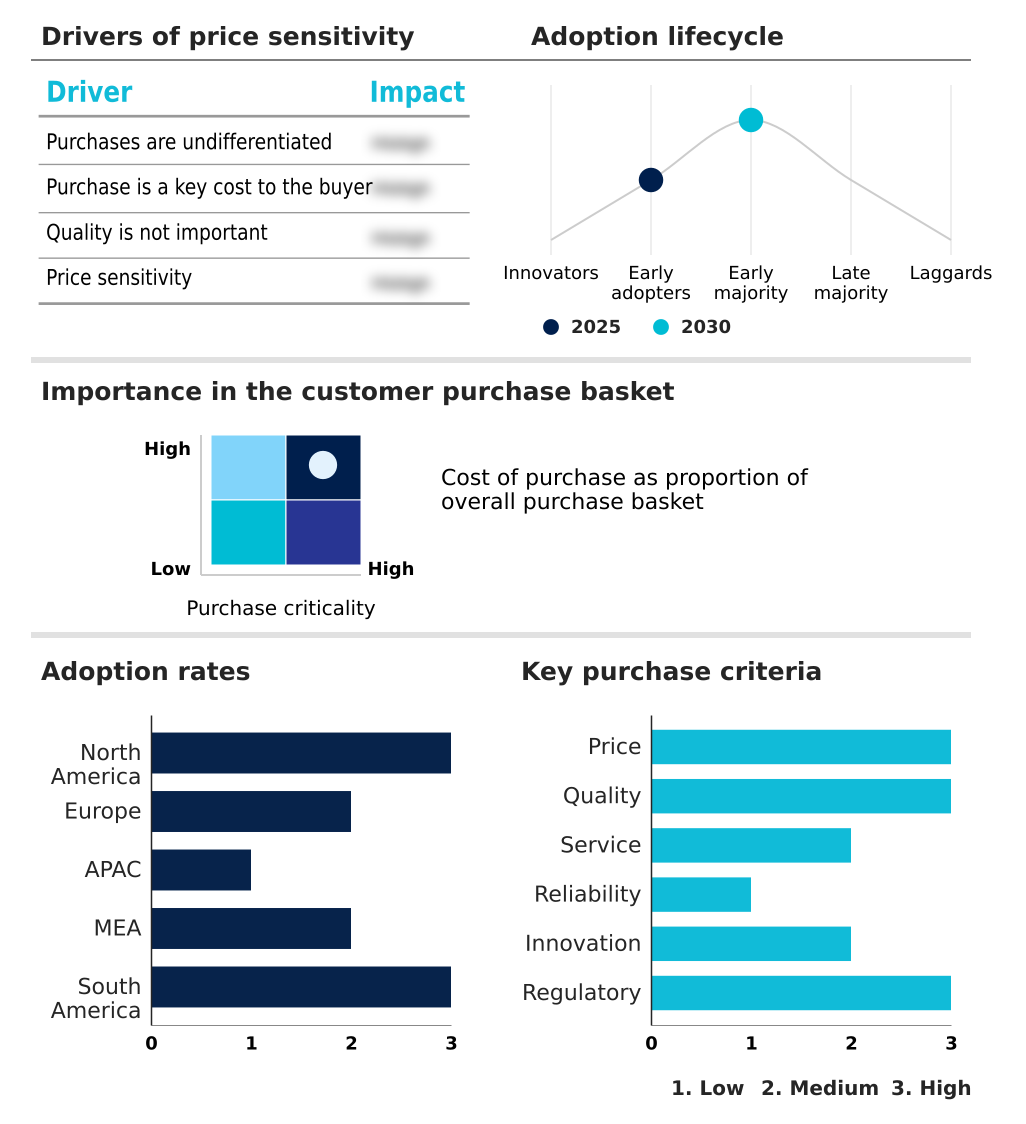
Customer Landscape of Synthetic Data Generation Software Industry
Competitive Landscape
Companies are implementing various strategies, such as strategic alliances, synthetic data generation software market forecast, partnerships, mergers and acquisitions, geographical expansion, and product/service launches, to enhance their presence in the industry.
Aetion Inc. - Offerings include specialized software for creating artificial datasets that replicate real-world statistical properties for privacy-safe analytics and advanced AI model training.
The industry research and growth report includes detailed analyses of the competitive landscape of the market and information about key companies, including:
- Aetion Inc.
- Capgemini SE
- Databricks Inc.
- GenRocket Inc.
- Google LLC
- Gretel AI
- K2View
- MDClone Ltd.
- MOSTLY AI
- NVIDIA Corp.
- Parallel Domain
- Rendered.ai
- SAS Institute Inc.
- Scale AI
- Synth Studio
- Synthesized Ltd
- Syntho
- Tonic AI Inc.
- Unity Technologies Inc.
- YData
Qualitative and quantitative analysis of companies has been conducted to help clients understand the wider business environment as well as the strengths and weaknesses of key industry players. Data is qualitatively analyzed to categorize companies as pure play, category-focused, industry-focused, and diversified; it is quantitatively analyzed to categorize companies as dominant, leading, strong, tentative, and weak.
Recent Development and News in Synthetic data generation software market
- In October 2025, Accenture acquired Decho, a UK-based consultancy, to bolster its AI and technology advisory services in sectors including healthcare and government.
- In November 2025, SAS Institute Inc. launched its SAS Data Maker solution on the Microsoft marketplace, expanding the accessibility of its synthetic data offerings.
- In April 2025, Tonic AI Inc. completed its acquisition of Fabricate, strengthening its position in the market for synthetic data solutions for software and AI development.
- In June 2025, Meta invested USD 14 billion in Scale AI to enhance its AI model training capabilities and data infrastructure.
Dive into Technavio’s robust research methodology, blending expert interviews, extensive data synthesis, and validated models for unparalleled Synthetic Data Generation Software Market insights. See full methodology.
| Market Scope | |
|---|---|
| Page number | 311 |
| Base year | 2025 |
| Historic period | 2020-2024 |
| Forecast period | 2026-2030 |
| Growth momentum & CAGR | Accelerate at a CAGR of 46.4% |
| Market growth 2026-2030 | USD 3053.6 million |
| Market structure | Fragmented |
| YoY growth 2025-2026(%) | 40.8% |
| Key countries | US, Canada, Mexico, Germany, UK, France, The Netherlands, Italy, Spain, China, India, Japan, South Korea, Australia, Indonesia, Saudi Arabia, UAE, South Africa, Israel, Turkey, Brazil, Argentina and Colombia |
| Competitive landscape | Leading Companies, Market Positioning of Companies, Competitive Strategies, and Industry Risks |
Research Analyst Overview
- The synthetic data generation software market is defined by its role in enabling privacy-safe innovation across industries. At its core, the technology leverages generative adversarial networks and variational autoencoders to facilitate secure data sharing environments and real-time synthetic data generation.
- The adoption of generative diffusion models is further advancing the creation of high-fidelity synthetic data, which is essential for AI model fine-tuning data and automated data augmentation. A key boardroom consideration is the use of digital twin simulation, which can eliminate millions in capital expenditures on physical testing facilities by using physics-based sensor data.
- The market addresses critical needs such as data privacy and compliance testing, software testing and QA, and fraud detection and cybersecurity. Ensuring cross-database consistency and robust synthetic data quality metrics are central to overcoming technical hurdles.
- Advanced techniques provide differential privacy guarantees, support algorithmic bias mitigation, and enable structured tabular data synthesis alongside synthetic time series data, synthetic text and NLP data, and synthetic image and video data.
- From data de-identification techniques and statistical property mirroring to real-world evidence simulation and synthetic population modeling, the technology provides the foundational data for autonomous systems training data while preventing model collapse.
What are the Key Data Covered in this Synthetic Data Generation Software Market Research and Growth Report?
-
What is the expected growth of the Synthetic Data Generation Software Market between 2026 and 2030?
-
USD 3.05 billion, at a CAGR of 46.4%
-
-
What segmentation does the market report cover?
-
The report is segmented by Data Type (Structured tabular data, Image and video data, Text and NLP data, and Time series and sensor data), End-user (BFSI, Healthcare and life sciences, Retail and e-commerce, Automotive and mobility, and Others), Application (AI and ML model training, Data privacy and compliance testing, Software testing and QA, and Fraud detection and cybersecurity) and Geography (North America, Europe, APAC, Middle East and Africa, South America)
-
-
Which regions are analyzed in the report?
-
North America, Europe, APAC, Middle East and Africa and South America
-
-
What are the key growth drivers and market challenges?
-
Escalating regulatory pressures to protect personal information, Maintaining data fidelity and preventing risk of model collapse
-
-
Who are the major players in the Synthetic Data Generation Software Market?
-
Aetion Inc., Capgemini SE, Databricks Inc., GenRocket Inc., Google LLC, Gretel AI, K2View, MDClone Ltd., MOSTLY AI, NVIDIA Corp., Parallel Domain, Rendered.ai, SAS Institute Inc., Scale AI, Synth Studio, Synthesized Ltd, Syntho, Tonic AI Inc., Unity Technologies Inc. and YData
-
Market Research Insights
- Market dynamics are shaped by the need for privacy-preserving data synthesis and generative AI for data creation. The use of synthetic data for ML models is a key factor, with a focus on creating realistic synthetic datasets for AI training data generation.
- Enterprises that adopt a synthetic data platform can accelerate development timelines by over 50% compared to traditional data acquisition methods. Furthermore, using synthetic financial data or synthetic healthcare data allows organizations to innovate while reducing compliance risks, with some achieving a 99% reduction in re-identification risk.
- The application of multi-modal synthetic data and edge case data generation is becoming crucial for developing robust and unbiased AI systems, delivering a clear competitive advantage.
We can help! Our analysts can customize this synthetic data generation software market research report to meet your requirements.
 RIA -
RIA - 
