
AI Training Dataset Market Size 2026-2030
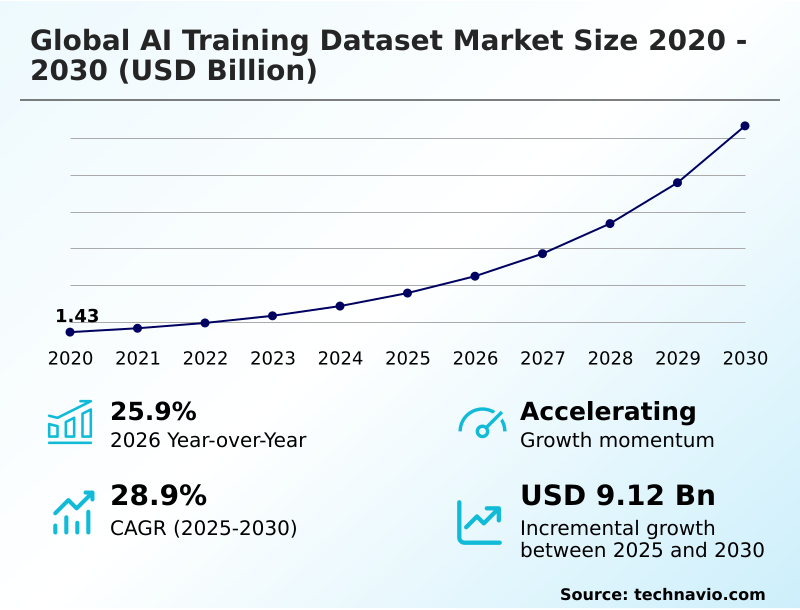
The ai training dataset market size is valued to increase by USD 9.12 billion, at a CAGR of 28.9% from 2025 to 2030. Expansion of multimodal large language models and generative AI will drive the ai training dataset market.
Major Market Trends & Insights
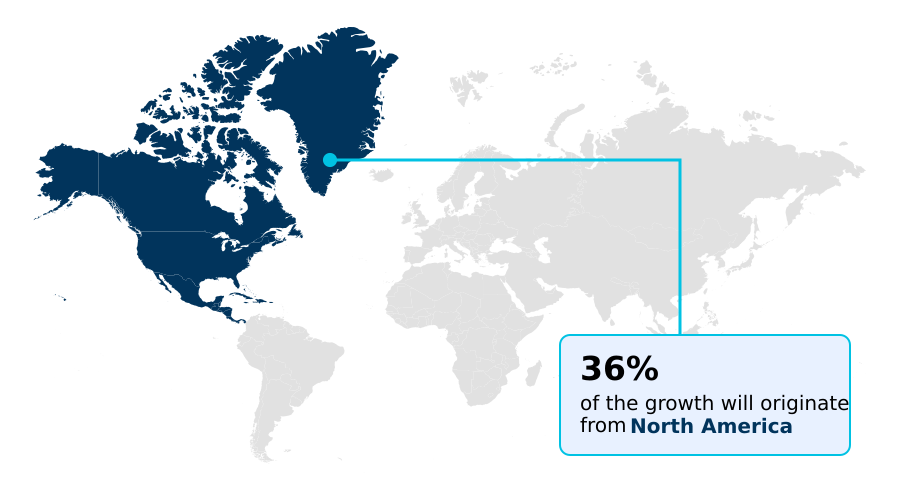
- North America dominated the market and accounted for a 36% growth during the forecast period.
- By Service Type - Text segment was valued at USD 1.22 billion in 2024
- By Deployment - On-premises segment accounted for the largest market revenue share in 2024
Market Size & Forecast
- Market Opportunities: USD 11.25 billion
- Market Future Opportunities: USD 9.12 billion
- CAGR from 2025 to 2030 : 28.9%
Market Summary
- The AI training dataset market is undergoing a structural transformation, moving beyond sheer data volume to prioritize high-fidelity, domain-specific information. This shift is propelled by the maturation of generative AI, which demands meticulously curated inputs for enhanced reasoning and reduced inaccuracies.
- The need for ethical data sourcing and robust data provenance tracking is paramount as enterprises deploy AI in mission-critical operations, increasing demand for licensed and consented datasets. In sectors like autonomous transportation, a business scenario involves using a combination of real-world and synthetic data to train models for complex edge cases, ensuring safety and reliability.
- This reliance on hybrid data strategies, blending human-annotated information with high-quality synthetic inputs, is becoming standard practice. Furthermore, the market is defined by the growing necessity for multimodal datasets that integrate text, image, and audio to support sophisticated applications, driving investment in advanced data annotation and management platforms that ensure both quality and compliance with evolving global privacy standards.
What will be the Size of the AI Training Dataset Market during the forecast period?
Get Key Insights on Market Forecast (PDF) Get Free Sample
How is the AI Training Dataset Market Segmented?
The ai training dataset industry research report provides comprehensive data (region-wise segment analysis), with forecasts and estimates in "USD million" for the period 2026-2030, as well as historical data from 2020-2024 for the following segments.
- Service type
- Text
- Image or video
- Audio
- Deployment
- On-premises
- Cloud
- Type
- Unstructured data
- Structured data
- Semi-structured data
- Geography
- North America
- US
- Canada
- Mexico
- APAC
- China
- Japan
- India
- Europe
- Germany
- UK
- France
- South America
- Brazil
- Argentina
- Colombia
- Middle East and Africa
- UAE
- Saudi Arabia
- South Africa
- Rest of World (ROW)
- North America
By Service Type Insights
The text segment is estimated to witness significant growth during the forecast period.
The global AI training dataset market 2026-2030 is segmented by deployment, service type, and data structure, reflecting a shift toward data-centric AI. Organizations leverage cloud-based data management for scalability and on-premises data infrastructure for security, particularly when handling high-fidelity data.
The market's function relies on robust data acquisition technologies and comprehensive data governance frameworks to manage unstructured data processing, structured data analytics, and semi-structured data parsing.
Adherence to data privacy compliance is crucial, as enterprises using well-governed datasets report up to a 30% improvement in model accuracy.
This segmentation underscores the industry's focus on curating precise and reliable data to fuel advanced machine learning applications across various verticals.
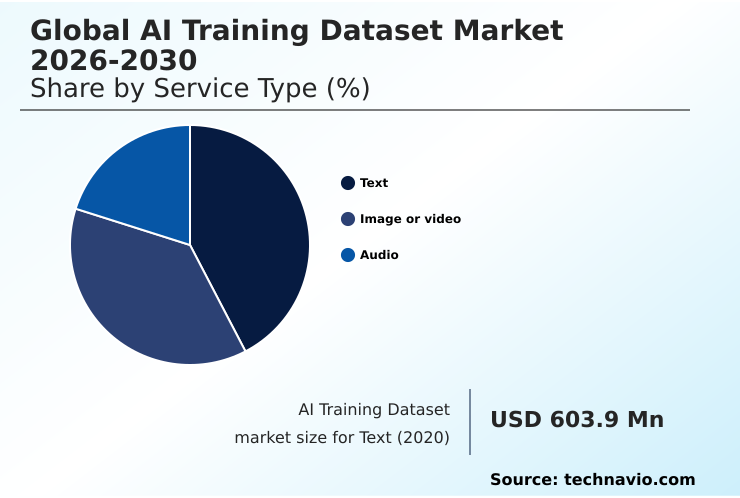
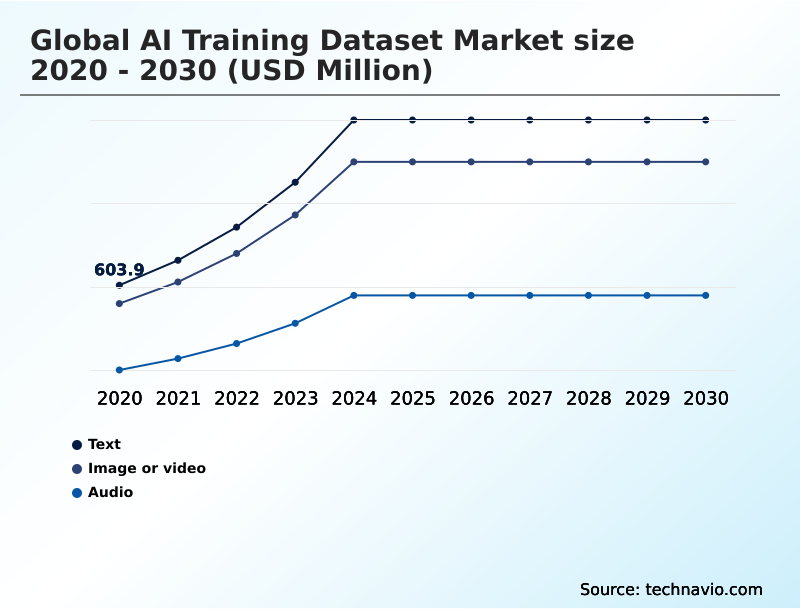
The Text segment was valued at USD 1.22 billion in 2024 and showed a gradual increase during the forecast period.
Regional Analysis
North America is estimated to contribute 36% to the growth of the global market during the forecast period.Technavio’s analysts have elaborately explained the regional trends and drivers that shape the market during the forecast period.
See How AI Training Dataset Market Demand is Rising in North America Get Free Sample
The geographic landscape of the global AI training dataset market 2026-2030 is led by North America, which drives innovation and accounts for over 36% of market expansion.
This region's dominance is fueled by its concentration of advanced research labs focusing on computer vision and natural language processing (NLP).
APAC is the fastest-growing region, with its data annotation services expanding at a rate 10% higher than the global average, specializing in tasks like semantic segmentation and named entity recognition.
Europe's market is defined by strict regulations, prioritizing ethical and privacy-compliant datasets for applications including sentiment analysis.
Growth in South America and the Middle East and Africa is driven by the digitalization of industries, creating demand for localized datasets for audio transcription and point-cloud segmentation.
Market Dynamics
Our researchers analyzed the data with 2025 as the base year, along with the key drivers, trends, and challenges. A holistic analysis of drivers will help companies refine their marketing strategies to gain a competitive advantage.
- The strategic importance of specialized datasets is expanding across multiple industries, creating distinct value chains. For instance, developing an AI training dataset for autonomous driving requires integrating massive volumes of sensor data, while medical imaging AI dataset requirements focus on pixel-perfect annotation and regulatory compliance.
- In parallel, financial services fraud detection datasets demand high-security protocols and the ability to model complex transactional patterns. The legal sector is another key area, where legal document analysis training data must be curated by subject-matter experts to interpret contractual nuances.
- Similarly, a retail customer behavior dataset for AI helps in personalizing user experiences, achieving customer segmentation with over 90% accuracy compared to traditional methods. The industrial sector leverages an AI dataset for manufacturing predictive maintenance to reduce equipment downtime. The adoption of synthetic data for healthcare privacy is accelerating, as is the use of RLHF for conversational AI alignment.
- Enterprises are also investing in multimodal datasets for robotics perception and high-quality audio data for transcription. The applications extend to using geospatial data for precision agriculture and unstructured text for sentiment analysis. The development of 3D point cloud data for AR/VR is a growing niche.
- Across all these areas, evaluating bias in training datasets remains a critical challenge, alongside effective data annotation for computer vision. Efforts are also being made in creating datasets for rare disease research, securing data for financial modeling, providing training data for speech recognition, managing data for industrial IoT, and building specific datasets for generative AI content.
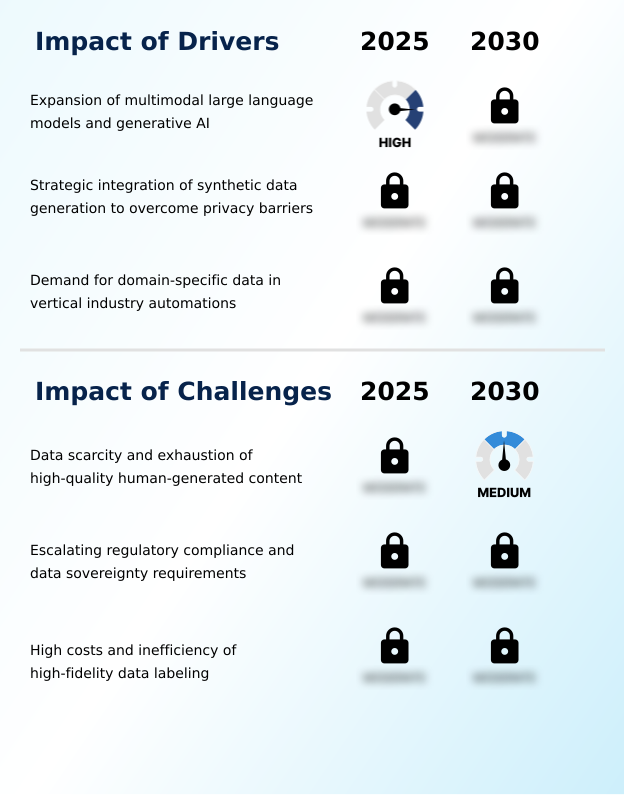
What are the key market drivers leading to the rise in the adoption of AI Training Dataset Industry?
- A key market driver is the expansion of multimodal large language models and generative AI, which require vast, diverse datasets to process text, images, and video simultaneously.
- The global AI training dataset market 2026-2030 is primarily driven by the expansion of generative AI, which demands vast and diverse inputs. This has intensified the need for advanced data labeling and data curation to ensure quality.
- A key driver is the strategic adoption of synthetic data generation, which accelerates project timelines by up to 50% by enabling rapid edge case simulation without compromising privacy. This addresses the limitations of relying solely on human-generated content.
- Furthermore, there is a rising demand for domain-specific datasets, as models trained on them achieve over 20% better performance in vertical industries.
- This specialization enhances model robustness and supports advanced techniques like zero-shot learning, reducing dependency on machine-generated content for future training cycles.
What are the market trends shaping the AI Training Dataset Industry?
- A significant trend is the proliferation of ethical data sourcing and provenance transparency, driven by the need to mitigate legal risks and ensure models are free from bias.
- Key trends are reshaping the global AI training dataset market 2026-2030, with a focus on quality and ethical integrity. The move toward ethical data sourcing and transparent data provenance is paramount, with firms prioritizing these practices seeing a 15% higher customer trust score. This involves new methods like digital watermarking for enhanced dataset traceability.
- Concurrently, the industrialization of reinforcement learning from human feedback (RLHF) is aligning models with human values, a process that has been shown to reduce harmful outputs by over 75% in initial tests. This expert-led data refinement is critical for capturing linguistic nuance.
- Another major shift is the adoption of temporal data fusion and multimodal data fusion, creating dynamic datasets that improve adversarial attack resilience and enable more sophisticated, real-world AI applications.
What challenges does the AI Training Dataset Industry face during its growth?
- A key challenge affecting industry growth is data scarcity and the potential exhaustion of high-quality human-generated content, which is critical for training robust AI models.
- The global AI training dataset market 2026-2030 faces significant hurdles that can impede innovation. The primary challenge is the risk of model collapse from training on low-quality data, making rigorous model validation and the use of pristine ground-truth data essential.
- Data sovereignty regulations create complexity, with compliance increasing project overhead by up to 25% due to localized data requirements and the need for robust data anonymization. Moreover, the high cost of data preparation remains a major barrier.
- The reliance on human-in-the-loop processes for quality still accounts for over half of all data preparation costs, even with the aid of model-assisted labeling. Efficient automated quality assurance and techniques like few-shot learning are critical to scaling operations without sacrificing accuracy in tasks such as speaker diarization.
Exclusive Technavio Analysis on Customer Landscape
The ai training dataset market forecasting report includes the adoption lifecycle of the market, covering from the innovator’s stage to the laggard’s stage. It focuses on adoption rates in different regions based on penetration. Furthermore, the ai training dataset market report also includes key purchase criteria and drivers of price sensitivity to help companies evaluate and develop their market growth analysis strategies.
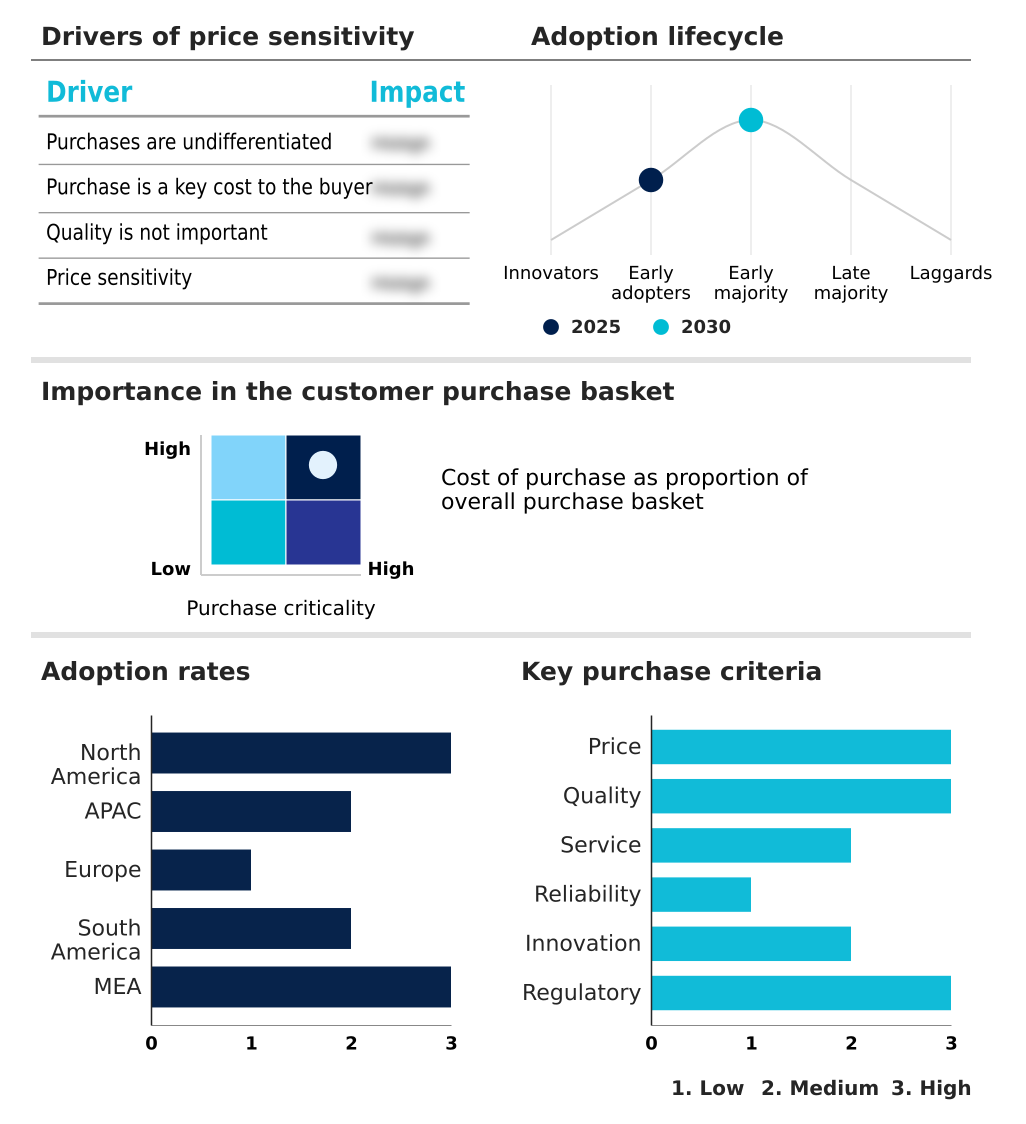
Customer Landscape of AI Training Dataset Industry
Competitive Landscape
Companies are implementing various strategies, such as strategic alliances, ai training dataset market forecast, partnerships, mergers and acquisitions, geographical expansion, and product/service launches, to enhance their presence in the industry.
ALEGION - Provides a highly reliable, scalable cloud infrastructure platform, offering AI training dataset services for dataset creation, labeling, and model management.
The industry research and growth report includes detailed analyses of the competitive landscape of the market and information about key companies, including:
- ALEGION
- Amazon Web Services Inc.
- APPEN Ltd.
- Cloudfactory
- Cogito Tech LLC
- Dataloop AI Ltd
- DefinedCrowd Corp.
- Google LLC
- IBM Corp.
- iMerit
- Labelbox
- Lionbridge Technologies LLC
- Microsoft Corp.
- NVIDIA Corp.
- Samasource
- Scale AI
- Snorkel AI Inc.
- SuperAnnotate
- TELUS Digital
- V7 Ltd.
Qualitative and quantitative analysis of companies has been conducted to help clients understand the wider business environment as well as the strengths and weaknesses of key industry players. Data is qualitatively analyzed to categorize companies as pure play, category-focused, industry-focused, and diversified; it is quantitatively analyzed to categorize companies as dominant, leading, strong, tentative, and weak.
Recent Development and News in Ai training dataset market
- In March, 2025, a consortium of global digital publishers established a unified technical standard to prevent automated crawlers from scraping high-value editorial content without explicit licensing.
- In March, 2025, the United States Department of Commerce expanded its AI Safety Institute consortium, incorporating specialized data curation partners to develop benchmark datasets for red-teaming advanced generative models.
- In May, 2025, a consortium of European cloud providers and industrial firms launched a decentralized data exchange platform, enabling secure sharing of training datasets for automotive and aerospace sectors without transferring data ownership.
- In February, 2025, Qatar's Ministry of Communications and Information Technology entered a formal collaboration with Scale AI to enhance government services by developing over fifty AI-driven use cases, leveraging local unstructured data.
Dive into Technavio’s robust research methodology, blending expert interviews, extensive data synthesis, and validated models for unparalleled AI Training Dataset Market insights. See full methodology.
| Market Scope | |
|---|---|
| Page number | 291 |
| Base year | 2025 |
| Historic period | 2020-2024 |
| Forecast period | 2026-2030 |
| Growth momentum & CAGR | Accelerate at a CAGR of 28.9% |
| Market growth 2026-2030 | USD 9121.0 million |
| Market structure | Fragmented |
| YoY growth 2025-2026(%) | 25.9% |
| Key countries | US, Canada, Mexico, China, Japan, India, South Korea, Australia, Singapore, Germany, UK, France, Italy, Spain, The Netherlands, Brazil, Argentina, Colombia, UAE, Saudi Arabia, South Africa, Israel and Nigeria |
| Competitive landscape | Leading Companies, Market Positioning of Companies, Competitive Strategies, and Industry Risks |
Research Analyst Overview
- The AI training dataset market is defined by a technical pivot towards sophisticated data types and processing methodologies. The proliferation of generative AI necessitates a focus on multimodal data fusion and temporal data fusion to build models that understand context and sequence.
- This trend is coupled with the critical adoption of synthetic data generation to overcome privacy hurdles and the scarcity of real-world examples, alongside the use of reinforcement learning from human feedback (RLHF) to align model behavior with human values.
- Boardroom decisions are increasingly influenced by the need for ethical data sourcing and transparent data provenance, which mitigates regulatory risk and builds consumer trust. Companies that master domain-specific datasets for applications like computer vision and natural language processing (NLP) are achieving a competitive edge, as evidenced by a 25% performance uplift in specialized tasks.
- Key operational processes include data annotation, data labeling, data curation, and robust model validation, often involving human-in-the-loop workflows. Addressing challenges like model collapse and ensuring data sovereignty are now central to strategic planning.
- Technologies such as semantic segmentation, point-cloud segmentation, and advanced data anonymization are becoming standard, while audio transcription, speaker diarization, named entity recognition, and sentiment analysis form the backbone of language-based AI systems.
What are the Key Data Covered in this AI Training Dataset Market Research and Growth Report?
-
What is the expected growth of the AI Training Dataset Market between 2026 and 2030?
-
USD 9.12 billion, at a CAGR of 28.9%
-
-
What segmentation does the market report cover?
-
The report is segmented by Service Type (Text, Image or video, and Audio), Deployment (On-premises, and Cloud), Type (Unstructured data, Structured data, and Semi-structured data) and Geography (North America, APAC, Europe, South America, Middle East and Africa)
-
-
Which regions are analyzed in the report?
-
North America, APAC, Europe, South America and Middle East and Africa
-
-
What are the key growth drivers and market challenges?
-
Expansion of multimodal large language models and generative AI, Data scarcity and exhaustion of high-quality human-generated content
-
-
Who are the major players in the AI Training Dataset Market?
-
ALEGION, Amazon Web Services Inc., APPEN Ltd., Cloudfactory, Cogito Tech LLC, Dataloop AI Ltd, DefinedCrowd Corp., Google LLC, IBM Corp., iMerit, Labelbox, Lionbridge Technologies LLC, Microsoft Corp., NVIDIA Corp., Samasource, Scale AI, Snorkel AI Inc., SuperAnnotate, TELUS Digital and V7 Ltd.
-
Market Research Insights
- The dynamics of the global AI training dataset market 2026-2030 are shaped by the strategic adoption of advanced data methodologies to enhance model performance. The adoption of data-centric AI approaches has demonstrated a capacity to reduce model errors by over 40%, emphasizing the value of high-fidelity data over sheer volume.
- Furthermore, expert-led data refinement processes can increase model performance in specialized domains by up to 25% compared to fully automated methods. This shift highlights the importance of combining human expertise with technology. Enterprises are increasingly investing in sophisticated data acquisition technologies and data governance frameworks to ensure both quality and data privacy compliance.
- This focus on structured, high-quality inputs is essential for building robust and reliable AI systems that can navigate complex, real-world scenarios effectively.
We can help! Our analysts can customize this ai training dataset market research report to meet your requirements.
 RIA -
RIA - 
